[Langchain] Chunk 분리 오류
[문제]
렝체인으로 여러 기사 내용을 담은 PDF 파일을 LLM( ChatGPT 모델)한테 학습시키기 위해
PDF파일 내용을 chunk로 분리하는 과정에서 문제 발생했다.
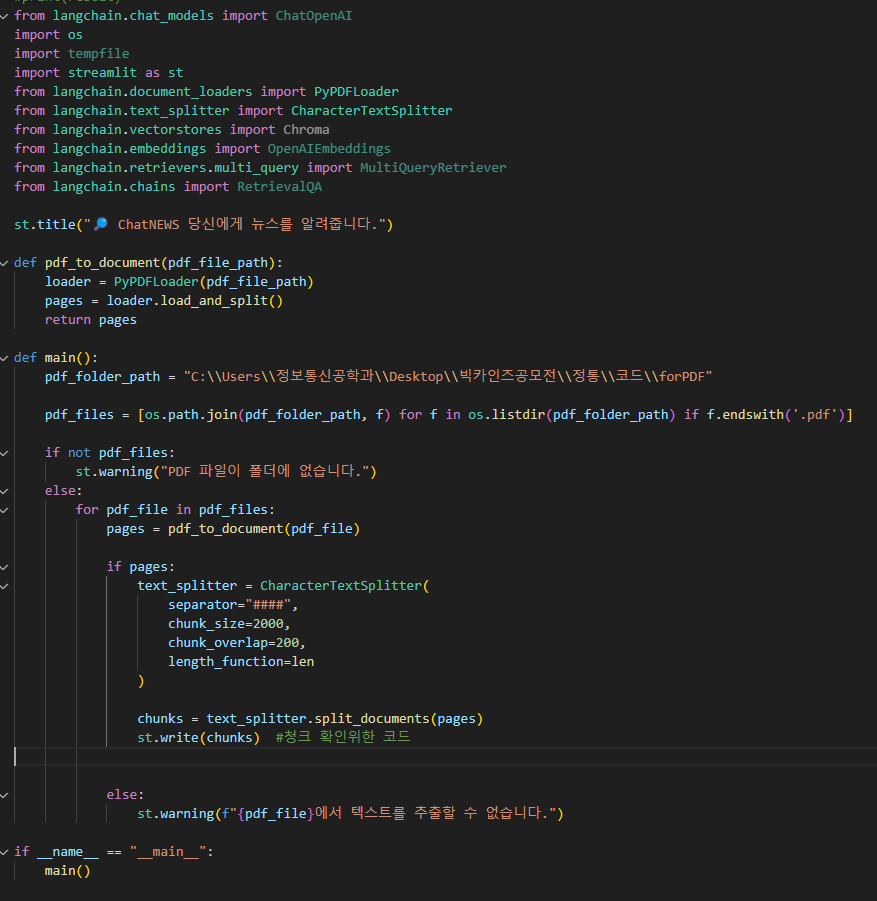

한 기사가 끝나고 다른 기사가 시작하는 부분에서 chunk로 분리하고 싶어서, 각 기사 제목 앞에 "####"라는 기호를
pdf에서 추가했다. 그래서 textSplitter의 separator = "####" 라는 파라미터로 구현해서 pdf파일 내용을 "####"를 단위로 chunk로 분리해야한다.
하지만 사진에서 'page'라는 속성을 확인하면, pdf파일 내용이 페이지단위로만 Chunk로 분리되고 있다는 것을 알 수 있다.
[문제 원인]
찾아보니까 CharacterTextSpliter가 원인이였다.CharacterTextSpliter가 오직 하나의 구분자로 텍스트를 chunk로 분리하는데, 나는 위에 코드에서 알 수 있듯이 이미 split.document로 페이지단위 즉, 페이지라는 구문자로 chunk로 분리했기 때문에 "####" 구분자가 무시당했다.
[해결]


CharacterTextSpliter 대신 RecursiveCharacterTextSpliter로 대체했다. RecursiveCharacterTextSpliter가 CharacterTextSpliter와 달리 구분자 하나가 아니라 여러 구분자를 기준으로 텍스트를 chunk로 분리할 수 있다.
그래서 원래 기본값으로 줄바꿈,쉼표, 마침표 등과 같은 구분자들 기준으로 분리하는데, 나는 separators = "#" 파라미터("####"에서 "#"로 바꿈)구분자를 초기화했다. 그래서 최종적으로 페이지와 기사 제목 앞에 있는 "#" 기호 기분으로 pdf파일 내용을 chunk로 분리할 수 있도록 고쳤다.